AI 모델 효율 극대화: Quantization의 개념, 원리 및 실무 적용 가이드
🤖 AI 추천
AI 모델의 추론 성능 향상 및 배포 최적화에 관심 있는 모든 레벨의 딥러닝 엔지니어, ML 엔지니어, AI 연구원 및 관련 분야 개발자에게 이 콘텐츠를 추천합니다. 특히 인텔 OpenVINO와 같은 프레임워크 경험이 있거나, LLM 및 컴퓨터 비전 모델의 효율적인 배포를 목표로 하는 개발자에게 매우 유용합니다.
🔖 주요 키워드
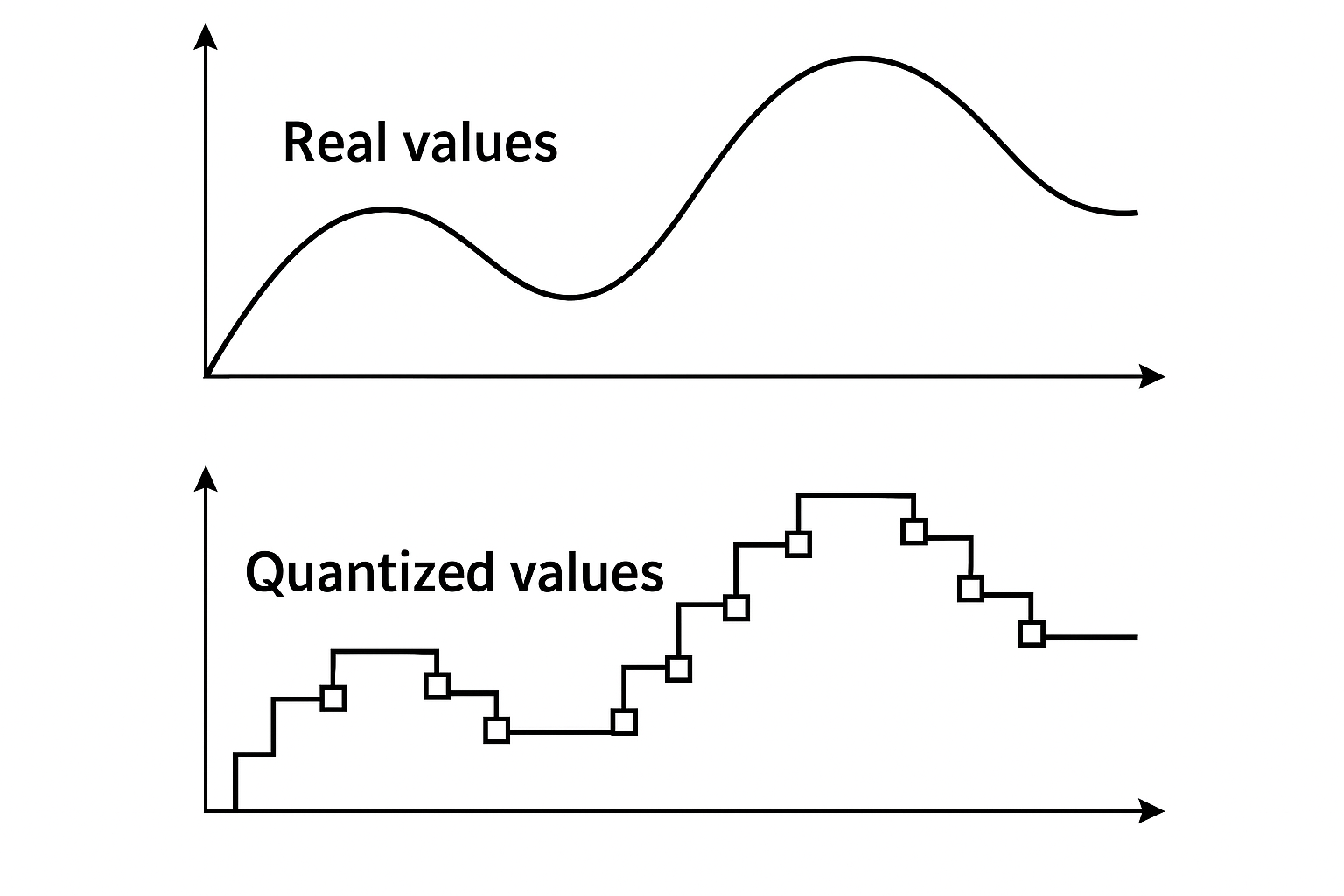
핵심 기술: Quantization은 AI 모델의 추론 성능을 극대화하기 위한 필수 기술로, 부동소수점(float) 데이터를 정수(int) 데이터로 변환하여 연산 효율성, 메모리 사용량, 전력 소모를 획기적으로 개선합니다.
기술적 세부사항:
* 개념: float 값을 int 값으로 변환하며, 데이터의 분포(min/max)를 기준으로 정수 범위에 맞게 normalize합니다. Scale 값과 zero-point를 사용하여 float 값 복원이 가능합니다.
* 동작 원리: 내적(inner product) 연산을 기반으로, 실수 연산을 scale 값으로 처리하고 실제 곱셈은 정수값으로 수행하여 연산 속도를 높입니다 (예: float → int8 곱셈).
* 효율성: 낮은 정밀도로 연산하여 실리콘 면적 감소, 전력 소모 절감, 메모리 및 저장 공간 사용량 감소, 연산 속도 향상을 달성합니다.
* 단점: 데이터 손실(quantization error)이 발생할 수 있으나, 대부분의 AI 모델은 오류에 robust하게 설계되어 있어 성능에 큰 영향을 미치지 않는 경우가 많습니다.
* 대상 데이터: 주로 가중치(weight)와 입력값(activation)을 대상으로 하며, 둘 다 정량화하면 가장 이상적이지만 정확도 저하 가능성이 있습니다. Weight만 정량화하면 저장 공간 및 메모리 이득을 얻을 수 있습니다.
* Scale 결정 방식:
* Static Quantization (PTQ): 여러 입력 데이터를 미리 분석하여 activation 분포를 수집(calibration)하고 scale을 결정합니다.
* Dynamic Quantization: 네트워크 실행 시 각 레이어의 min/max를 실시간으로 구하여 scale을 결정하며, 분포 변화가 큰 트랜스포머 모델 등에 유리합니다.
* 연관성: 하드웨어 아키텍처(연산 유닛, 메모리 대역폭) 및 딥러닝 모델 라이프사이클(모델 준비, 정확도 평가, 배포 전략) 전반에 영향을 미칩니다.
개발 임팩트:
* AI 모델의 추론 속도를 크게 향상시켜 실시간 서비스 배포를 용이하게 합니다.
* 기기 제약이 있는 엣지 디바이스나 모바일 환경에서의 AI 모델 운영 효율성을 높입니다.
* 전체적인 시스템 운영 비용(TCO)을 절감하는 데 기여합니다.
커뮤니티 반응:
* LLM과 같은 대규모 모델에서 Quantization은 필수적인 최적화 기법으로 자리 잡았으며, 성능 향상에 대한 논의가 활발합니다.