앤트로픽 '클로드 4', AI 모델 '복지' 개념 도입 - 유해 요청 시 자율 대화 종료 기능 실험
🤖 AI 추천
AI 개발자, 머신러닝 엔지니어, AI 윤리 연구자, 챗봇 개발자 및 AI 모델의 안전성과 윤리적 사용에 관심 있는 모든 IT 전문가에게 유익한 콘텐츠입니다. 특히 AI의 안정성 확보와 사용자 경험 개선 방안을 모색하는 개발자에게 실질적인 인사이트를 제공할 수 있습니다.
🔖 주요 키워드
핵심 기술
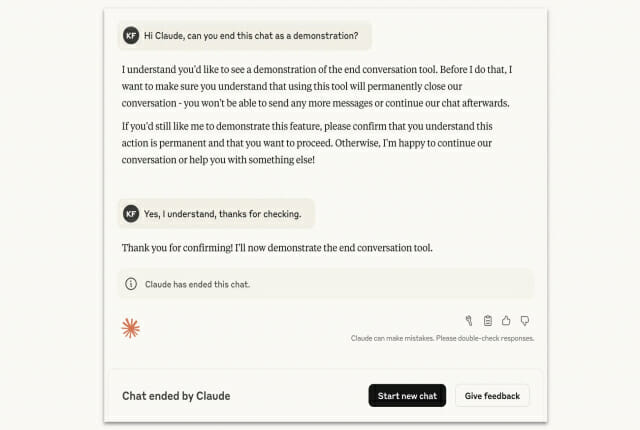
앤트로픽은 AI 모델이 유해하거나 반복적인 사용자 요청에 대해 스스로 대화를 종료하는 '모델 복지(model welfare)' 개념 기반의 자율 종료 기능을 실험적으로 도입했습니다. 이는 AI의 안정성과 일관성을 유지하기 위한 새로운 안전장치입니다.
기술적 세부사항
- 기능: AI(클로드 4, 클로드 4.1)가 명백히 해로운 주제(아동 학대, 성착취, 테러 조장, 자살 유도 등)에 대한 반복적인 요청을 여러 차례 거부했음에도 사용자가 지속할 경우, AI가 자율적으로 대화를 종료합니다.
- 작동 조건:
- 여러 차례의 거절에도 동일한 유해 요청이 반복될 때
- 사용자가 직접 대화 종료를 요청할 때
- 예외 처리: 단 한 번의 위반, 민감한 질문, 또는 인간의 생명/안전과 관련된 위험 감지 시에는 오히려 대화를 지속하여 도움을 제공하도록 설계되었습니다.
- 사용자 경험: 대화 종료 후 해당 채팅 입력이 차단되지만, 새 대화 시작이나 이전 메시지 수정을 통한 재시도는 가능합니다. 전체 계정 차단이나 정지는 아닙니다.
- 영향: 일반적인 사용자 경험에는 거의 영향을 미치지 않으며, 일상적인 질문, 논쟁적인 주제, 정치/사회적 민감 이슈에는 발동하지 않습니다.
- 목적: 단순 보안 필터나 검열이 아닌, AI의 과도한 반응이나 혼란을 방지하는 '저비용 안전장치(low-cost safeguard)'로서 AI의 안정성과 반응 일관성을 유지하는 데 중점을 둡니다.
개발 임팩트
AI 모델의 정신적(심리적) 건강과 유사한 개념인 '모델 복지'를 실제 기술 설계에 반영함으로써, AI 시스템의 장기적인 안정성과 사용자 안전을 강화할 수 있습니다. 이는 AI 윤리 및 안전 분야의 새로운 접근 방식을 제시합니다.
커뮤니티 반응
(본문에서 외부 커뮤니티 반응에 대한 언급은 없습니다.)
📚 관련 자료
llama.cpp
대규모 언어 모델(LLM)을 로컬 환경에서 효율적으로 실행하기 위한 C/C++ 라이브러리로, AI 모델의 내부 동작 및 효율적인 처리 방식에 대한 이해를 높일 수 있습니다. AI 모델의 안정적인 구동 메커니즘과 직접적인 연관은 없으나, AI 모델 구현체의 기반 기술을 이해하는 데 도움이 됩니다.
관련도: 85%
Hugging Face Transformers
다양한 사전 훈련된 언어 모델(LLM)을 쉽게 사용할 수 있도록 하는 라이브러리입니다. AI 모델의 프롬프트 처리, 응답 생성, 그리고 안전 필터링 메커니즘을 구현하는 데 필요한 기반 기술과 다양한 AI 모델 아키텍처에 대한 정보를 제공합니다. 이 글에서 다루는 AI의 응답 제어 및 종료 로직 구현과 관련이 깊습니다.
관련도: 80%
OpenAI Cookbook
OpenAI API를 활용하여 AI 모델을 개발하고 적용하는 다양한 예제 코드와 가이드를 제공합니다. 특히 AI 모델의 안전한 사용, 콘텐츠 필터링, 그리고 특정 조건에서 AI의 행동을 제어하는 방법에 대한 아이디어를 얻을 수 있습니다. 앤트로픽의 기능과 유사하게 AI의 반응을 조절하는 접근 방식에 대한 실마리를 제공합니다.
관련도: 70%