CacheBlend: Transformer KV Cache의 효율적인 재사용 및 최적화를 통한 LLM 추론 성능 향상
🤖 AI 추천
LLM 추론 성능 최적화, 특히 RAG(Retrieval Augmented Generation) 시스템을 구축하거나 개선하려는 백엔드 개발자, AI 엔지니어, 연구원에게 유익합니다. LLM 서빙 인프라를 다루는 DevOps 엔지니어에게도 관련성이 높습니다.
🔖 주요 키워드
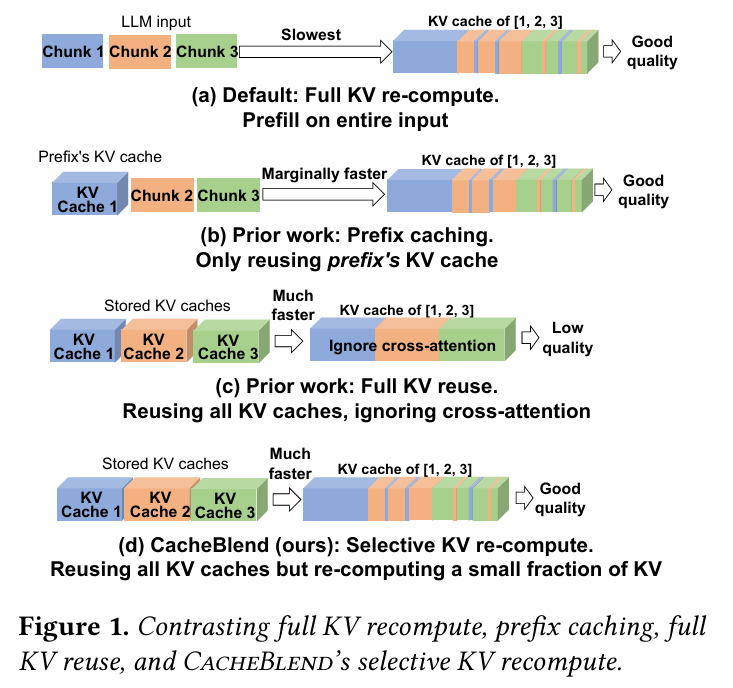
핵심 기술: CacheBlend는 Transformer 모델의 KV Cache 재사용 효율성을 극대화하여 LLM 추론 속도를 크게 향상시키는 기술입니다. 특히 RAG와 같이 복잡한 입력이 자주 사용되는 시나리오에서, 전체 KV Cache를 매번 다시 계산하는 대신 핵심적인 부분만 선별적으로 재계산(Selective Recomputation)함으로써 품질 저하를 최소화하면서 성능을 개선합니다.
기술적 세부사항:
* Prefix Caching 문제점: RAG 환경에서 자주 발생하는 문서 청크(chunk)들에 대한 Prefix Caching의 한계를 지적합니다. 기존 방식들은 첫 청크만 캐싱하거나(b), 모든 청크를 캐싱하되 cross-attention을 무시(c)하는 문제가 있었습니다.
* KV Deviation & Attention Deviation: 토큰별 KV 값의 차이(KV Deviation)와 Attention Matrix의 차이(Attention Deviation)를 측정하여 재계산이 필요한 토큰을 식별하는 메트릭을 사용합니다.
* HKVD (High-KV-Deviation) 토큰: KV Deviation이 높은 토큰을 HKVD 토큰으로 정의하고, 이 토큰들을 중심으로 Selective Recomputation을 수행합니다. 실험 결과, 10~20%의 HKVD 토큰만으로도 Attention Deviation이 크게 개선됨을 보였습니다.
* Attention Sparsity: Attention 값이 특정 토큰들에 집중되는 Attention Sparsity 특성 때문에, 한 레이어에서 HKVD가 발생한 토큰은 다음 레이어에서도 HKVD일 확률이 높다는 인사이트를 활용합니다.
* KV Cache Load Controller: 재계산에 소요되는 시간과 KV Cache 로딩 시간을 비교하여 최적의 재계산 비율(r%)을 동적으로 결정하고, 저장 장치(NVMe SSD 등) 선택을 통해 지연 시간을 최소화하는 컨트롤러를 설계했습니다.
* System Design: Loading Controller, KV Cache Store, Cache Fusor 등의 컴포넌트를 통해 전체적인 KV Cache 관리 및 재계산 파이프라인을 구성합니다.
개발 임팩트:
* TTFT(Time To First Token)를 기존 대비 2.2x ~ 3.3x 감소시켰습니다.
* Full KV Cache Reuse 대비 F1 및 Rouge-L 점수를 0.15 ~ 0.35까지 향상시키면서도, Full Computation이나 Prefix Caching 대비 품질 저하는 0.01 ~ 0.03 수준으로 미미합니다.
* LLM 추론의 비용 효율성과 속도를 크게 개선하여, RAG와 같은 복잡한 LLM 애플리케이션의 실제 서비스 적용 가능성을 높입니다.
커뮤니티 반응:
* EuroSys'25 베스트 페이퍼로 선정될 만큼 기술적 혁신성과 실용성을 인정받았습니다.
* LM Cache 오픈소스 프로젝트와 연계되어 vLLM과 함께 사용될 수 있어 실제 적용이 용이합니다.