컴파일러 기초: Lexer 구현 및 동작 원리 분석
🤖 AI 추천
컴파일러의 첫 단계인 Lexer(토크나이저)의 구현 원리를 배우고 싶은 초중급 개발자 및 컴퓨터 공학 전공 학생
🔖 주요 키워드
핵심 기술
이 문서는 컴파일러의 첫 단계인 Lexical Analysis (Lexer 또는 Tokenizer)의 구현 원리를 C++ 코드를 중심으로 상세하게 설명하며, 입력 문자열을 의미 있는 토큰 단위로 분리하는 과정을 다룹니다.
기술적 세부사항
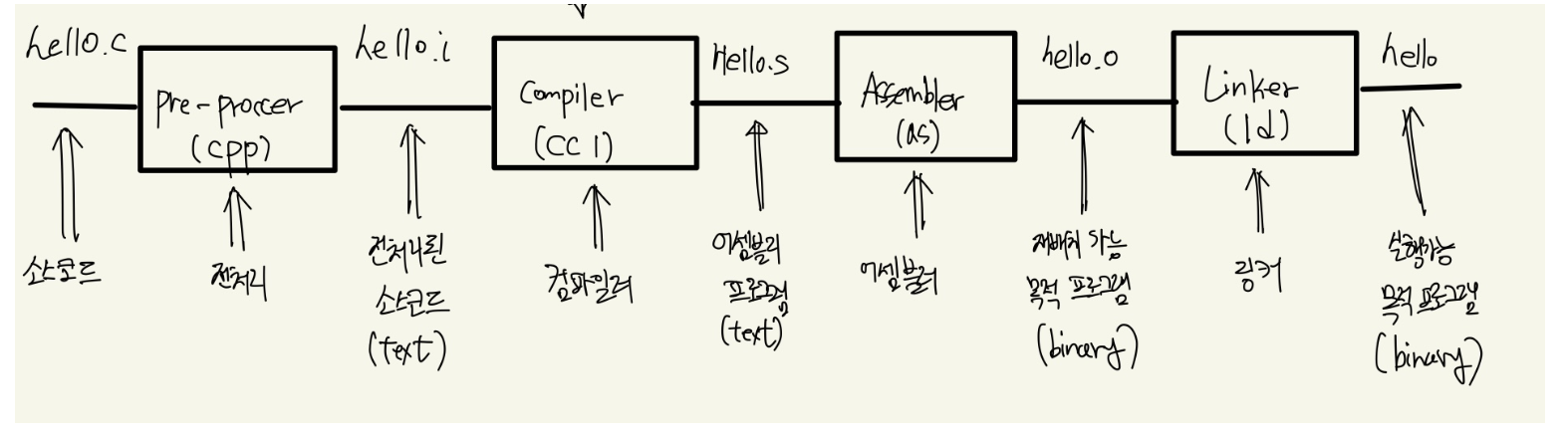
- 컴파일러 단계별 설명: 전처리, 컴파일 (Lexical Analysis, Syntax Analysis, Semantic Analysis, IR 생성 및 최적화, Target 코드 생성), 어셈블러, 링커 등 컴파일러의 전체적인 파이프라인을 간략하게 소개합니다.
- Lexer의 역할: 소스 코드를 문자 단위로 읽어들여, 숫자, 연산자, 괄호 등의 '토큰(Token)'으로 분리하는 작업을 수행합니다.
- 토큰(Token) 구조:
TokenType(e.g., NUMBER, PLUS, MINUS)과value(e.g., "12", "+")를 포함하는Token구조체 정의를 제시합니다. - Lexer 클래스 구현:
- 입력 문자열(
text)과 현재 파싱 위치(pos)를 멤버 변수로 가집니다. is_space(): 공백 문자를 구분하는 헬퍼 함수를 구현합니다.is_digit(): 숫자 문자를 구분하는 헬퍼 함수를 구현합니다.getNextToken(): 문자열을 순회하며 각 문자를 분석하여 토큰을 반환합니다.- 공백은 건너뜁니다.
- 연속된 숫자는 하나의
NUMBER토큰으로 처리합니다. - 기호 문자들은 해당 연산자 토큰으로 처리합니다.
- 알 수 없는 문자는 오류를 발생시킵니다.
- 문자열의 끝에 도달하면
END토큰을 반환합니다.
- 입력 문자열(
- 예제 코드:
hello.c와 같은 간단한 코드 예시를 통해 전처리 단계를 설명하고,12*(34+56)과 같은 입력 문자열을Lexer를 통해 토큰화하는 과정을 보여줍니다.
개발 임팩트
- 프로그래밍 언어의 내부 동작 방식에 대한 기본적인 이해를 높일 수 있습니다.
- 간단한 파서(Parser)와 함께 기본적인 언어 해석기를 직접 구현해볼 수 있는 기반을 마련합니다.
- 소프트웨어 개발자가 컴파일러와 링커의 역할을 이해하는 데 도움을 줍니다.
커뮤니티 반응
- 원본 텍스트에서 특정 커뮤니티 반응에 대한 언급은 없으나, 컴파일러와 관련된 주제는 개발 커뮤니티에서 꾸준히 높은 관심을 받고 있습니다.
톤앤매너
- 전문적이고 교육적인 톤으로, 복잡한 컴파일러의 첫 단계를 쉽게 이해할 수 있도록 안내합니다.
📚 관련 자료
rust-lang/rustc
Rust 컴파일러인 rustc는 매우 복잡하고 정교한 Lexer 및 Parser를 포함하고 있습니다. 이 저장소를 통해 실제 대규모 컴파일러가 어떻게 구축되는지, 그리고 Rust와 같은 언어의 Lexing 로직을 참고할 수 있습니다.
관련도: 70%
gcc-mirror/gcc
GNU Compiler Collection (GCC)은 C, C++ 등 다양한 언어를 지원하는 사실상의 표준 컴파일러입니다. GCC의 소스 코드를 통해 Lexer 및 Parser의 구현을 심층적으로 분석할 수 있습니다.
관련도: 65%
antlr/antlr4
ANTLR (Another Tool for Language Recognition)은 Java, C++, Python 등 다양한 언어로 파서를 생성하는 도구입니다. ANTLR 자체는 Lexer 생성기도 포함하며, 언어 정의 파일을 통해 Lexer/Parser를 쉽게 만들 수 있도록 지원하여 컴파일러 설계 학습에 유용합니다.
관련도: 80%