카카오 Kanana-v-3b: 한국어 특화 경량 멀티모달 언어모델 오픈소스 공개
🤖 AI 추천
한국어 및 멀티모달 AI 모델 개발에 관심 있는 AI 연구원, 개발자, 데이터 과학자, 그리고 한국 문화 및 언어 이해 능력이 중요한 서비스 개발 담당자에게 유용합니다. 특히 경량 모델 개발 및 성능 최적화에 관심 있는 분들에게 좋은 인사이트를 제공합니다.
🔖 주요 키워드
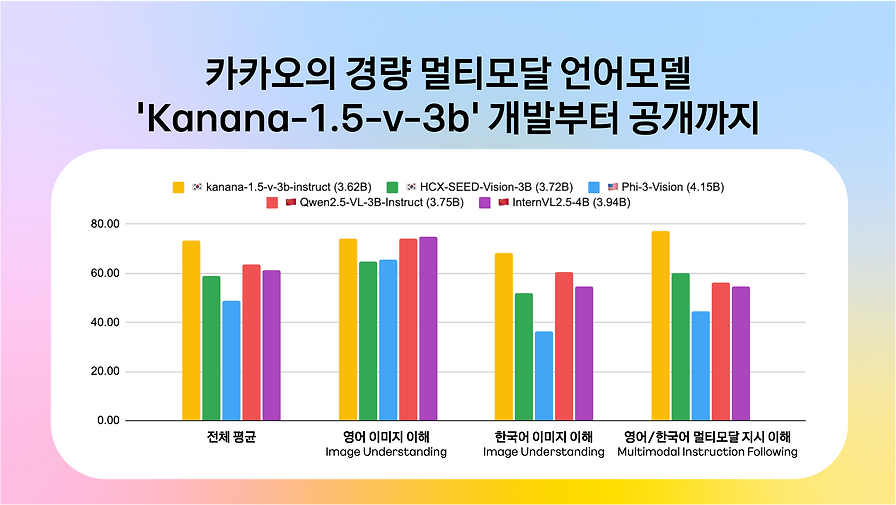
핵심 기술: 카카오의 Kanana 조직에서 개발한 경량 멀티모달 언어모델 'Kanana-v-3b'는 이미지와 텍스트를 함께 입력받아 자연어로 응답을 생성하며, 특히 한국어 및 한국 문화에 대한 이해도를 높이는 데 중점을 두었습니다. 이 모델은 허깅페이스를 통해 오픈소스로 공개되어 상업적 활용이 가능합니다.
기술적 세부사항:
- 모델 아키텍처: 카카오의 자체 언어모델 'Kanana-1.5-3b-instruct'를 기반으로, ViT(Vision Transformer) 기반 Vision Encoder와 자체 개발 C-Abstractor 구조를 활용하여 이미지 정보를 LLM이 이해할 수 있는 형태로 변환합니다.
- 모델 크기: 약 3.6B (36억 개) 파라미터를 가지는 경량 모델로, 4B 미만의 유사 규모 글로벌 모델과 비교하여 뛰어난 성능을 보입니다.
- 주요 학습 전략:
- 큰 모델의 지식을 경량 모델에 전달하는 지식 증류(Knowledge Distillation) 기법을 활용했습니다.
- 멀티모달 지시 이행(Multimodal Instruction Following) 능력 향상에 집중하여, 사용자의 복잡하고 직관적인 자연어 지시를 정확히 이해하고 따르도록 학습시켰습니다.
- 인간 선호 정렬 학습(Human Preference Alignment)을 통해 사용감 좋은 모델을 개발했습니다.
- 한국어 및 한국 문화 특화:
- 영어 벤치마크인 MIA-Bench를 한국어 환경에 맞게 수정하고 문화적 맥락을 반영한 MIA-Bench-Ko를 자체 구축하여 성능을 평가했습니다.
- 한국어 문자 인식(KoOCRBench), 차트 해석(KoChartTask), 한국 음식/의료 관련 텍스트 이해(KoFoodMenu, KoCosMed), 한국 문화/지식 기반 질의응답(KoMMDBench, KoEntity, KoCelebV2), 한국어 문제 풀이(KoExam, KoMathSol) 등 총 7종의 자체 한국어 벤치마크를 제작하여 모델 성능을 다각도로 측정했습니다.
- 기능 및 사용 예시:
- 뛰어난 지시 이행 능력
- 한국 문화에 대한 깊이 있는 이해
- 이미지 속 텍스트 인식 (OCR)
- 차트 및 표 인식
- 수학 문제 풀이
개발 임팩트: Kanana-v-3b는 영어 및 한국어 벤치마크에서 비슷한 크기의 글로벌 모델 대비 우수한 성능을 보여주며, 특히 한국어 관련 작업에서 압도적인 성능 차이를 기록했습니다. 이는 실제 한국 서비스 환경에서의 AI 모델 활용 가능성을 크게 높이며, 글로벌 AI 시장에서 한국형 모델의 경쟁력을 입증합니다. 향후 추론 능력 강화를 통해 STEM 분야에서의 성능 향상을 목표로 합니다.
커뮤니티 반응: 허깅페이스를 통한 모델 오픈소스로 공개되어 개발자 커뮤니티의 접근성을 높이고 활용을 장려하고 있습니다.
📚 관련 자료
transformers
Hugging Face의 Transformers 라이브러리는 다양한 언어 모델 및 멀티모달 모델의 사전 학습, 파인튜닝, 추론을 지원하는 핵심 라이브러리입니다. Kanana-v-3b 모델의 공개 및 활용에 직접적으로 연관됩니다.
관련도: 95%
pytorch-lightning
PyTorch Lightning은 PyTorch 기반의 딥러닝 모델 학습을 간소화하고 재현성을 높이는 프레임워크입니다. Kanana-v-3b와 같은 대규모 모델 학습 시 효율적인 실험 관리 및 코드 구조화에 사용될 수 있습니다.
관련도: 70%
Vision-Encoder-LLM
MMPretrain은 Vision Transformer(ViT)를 포함한 다양한 비전 모델을 위한 프레임워크를 제공합니다. Kanana-v-3b의 Vision Encoder 부분 학습 및 구현과 관련하여 참고할 수 있는 오픈소스 프로젝트입니다.
관련도: 80%