MySQL 성능 최적화: 대량 데이터 환경에서의 페이징 및 JOIN 성능 개선 사례
🤖 AI 추천
대량의 데이터를 처리하는 애플리케이션에서 발생하는 성능 병목 현상을 경험하고 있거나, 데이터베이스 쿼리 최적화 및 페이징 전략에 대해 깊이 이해하고 싶은 백엔드 개발자에게 이 콘텐츠를 추천합니다. 특히 실제 운영 환경에서 발생할 수 있는 다양한 성능 이슈와 그 해결 과정을 통해 실질적인 도움을 얻을 수 있습니다.
🔖 주요 키워드
핵심 기술
대규모 데이터베이스 환경에서 발생할 수 있는 API 응답 속도 지연 문제를 해결하기 위해 MySQL 쿼리 최적화, 인덱스 활용, 페이징 전략 개선에 대한 실질적인 경험과 분석 결과를 공유합니다.
기술적 세부사항
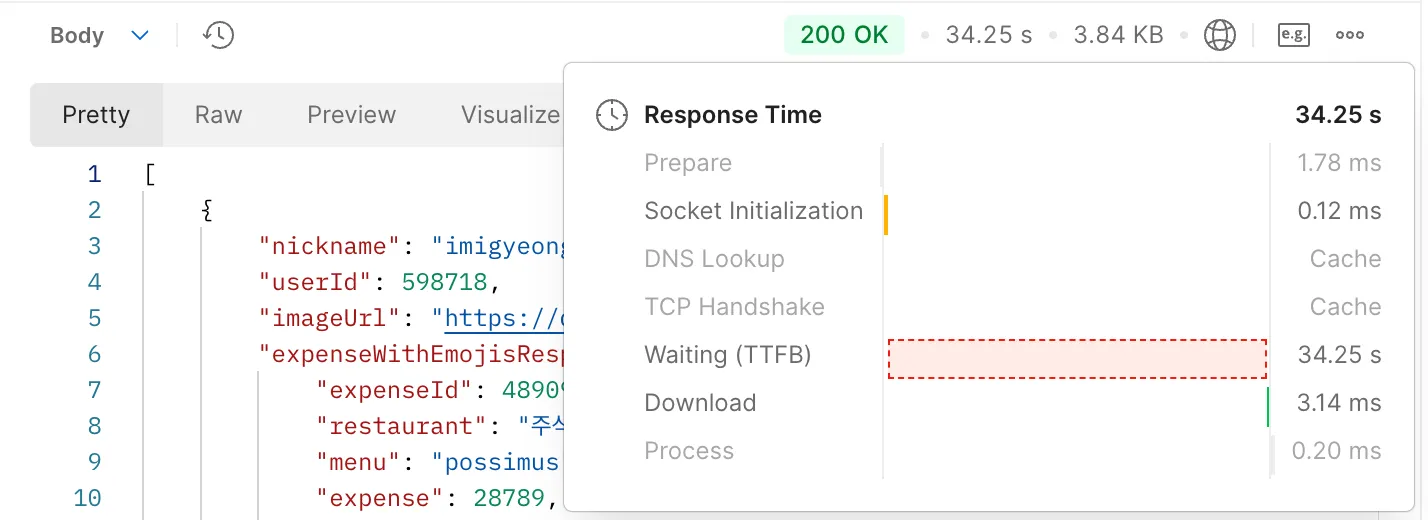
- 문제 정의: 100만 유저, 400만 목표, 1000만 지출 내역 등 대규모 데이터 환경에서 특정 API(
/api/community/expenses?page=0&size=10)의 응답 속도가 34초로 매우 느린 현상 발생. - 초기 분석:
EXPLAIN ANALYZE를 통해expense테이블의created_at필드에 대한 내림차순 정렬(Sort) 작업이 1000만 건의 데이터를 처리하며 성능 저하의 주요 원인임을 파악. - 1차 최적화:
expense테이블에created_at내림차순 인덱스(idx_expense_created_at_desc) 생성. (34s → 6s로 개선) - 2차 분석 및 최적화: 페이징 시 발생하는 불필요한
COUNT쿼리를 확인하고, 반환 타입을Page에서Slice로 변경하여COUNT쿼리 제거. (6s → 72ms로 개선) - 추가 성능 이슈 발견:
page번호가 커질수록(예: 10000) 다시 성능 저하 발생. Offset 기반 페이징의 한계를 확인. - 해결 방안: 정책적으로 대규모 페이지 조회를 제한하는 방식으로 접근 (예: 1000페이지 이상 조회 시 예외 발생).
- 학습 내용: 대량 데이터 성능 테스트의 중요성, 인덱스의 강력한 튜닝 효과, 페이징 최적화 전략 (Slice 사용, Offset 문제 인지).
개발 임팩트
- 대규모 데이터를 다루는 API의 응답 속도를 획기적으로 개선하여 사용자 경험 향상.
- 데이터베이스 쿼리 실행 계획 분석 및 최적화 능력 강화.
- 효율적인 페이징 구현을 위한 지식 습득 및 적용.
커뮤니티 반응
- (본문 내용에는 직접적인 커뮤니티 반응 언급 없음)
톤앤매너
실무에서 겪을 수 있는 성능 문제와 그 해결 과정을 상세히 공유하며, 기술적인 분석과 함께 실질적인 개선 방안을 제시하는 전문적인 톤을 유지합니다.
📚 관련 자료
MySQL
이 콘텐츠는 MySQL 데이터베이스의 성능 최적화 기법, 특히 인덱스 생성과 쿼리 실행 계획 분석에 대한 내용을 다루고 있습니다. MySQL 서버 자체의 동작 방식과 성능 특성을 이해하는 데 도움이 됩니다.
관련도: 95%
Hibernate
콘텐츠에서 언급된 `@Query`와 `Slice`, `Pageable`은 Spring Data JPA와 Hibernate ORM의 기능을 활용한 예시입니다. Hibernate의 Fetch Join 및 페이징 처리 메커니즘을 이해하는 데 관련성이 높습니다.
관련도: 85%
MySqlPerformance
MySQL 성능 튜닝에 대한 일반적인 도구 및 기법을 다루는 저장소입니다. 본 콘텐츠에서 제시된 `EXPLAIN ANALYZE` 사용 및 인덱스 생성과 같은 실질적인 튜닝 방법을 더 탐구하는 데 참고할 수 있습니다.
관련도: 70%