타이타닉 생존자 예측: Logistic Regression 기반 데이터 분석 및 모델링 인사이트
🤖 AI 추천
머신러닝 입문자, 데이터 과학자, Python 기반 데이터 분석 및 모델링 경험을 쌓고자 하는 개발자들에게 특히 추천합니다. Logistic Regression의 원리와 실제 데이터셋 적용 방법을 배우고 싶은 분들에게 유용합니다.
🔖 주요 키워드
타이타닉 생존자 예측: Logistic Regression 기반 데이터 분석 및 모델링 인사이트
핵심 기술: 본 콘텐츠는 타이타닉 생존자 데이터를 활용하여 Logistic Regression 모델을 구축하고, 데이터 전처리부터 모델 평가까지 전 과정을 상세히 다룹니다. 머신러닝의 기초를 다지는 데 탁월한 실습 예시를 제공합니다.
기술적 세부사항:
- 데이터셋: Kaggle에서 제공하는 타이타닉 생존자 데이터셋을 사용합니다.
- 탐색적 데이터 분석 (EDA): 생존율에 영향을 미치는 요인(성별, 객실 등급, 나이 등)을 시각화 및 통계적으로 분석합니다.
- 데이터 전처리:
- 결측치 처리 (예: 나이, 선실 정보)
- 범주형 변수 인코딩 (예: 성별, 탑승 항구)
- 불필요한 피처 제거
- 모델 구축: Logistic Regression 모델을 Scikit-learn 라이브러리를 사용하여 구현합니다.
- 모델 학습: 전처리된 데이터를 학습 데이터와 테스트 데이터로 분리하여 모델을 학습시킵니다.
- 모델 평가:
- 정확도 (Accuracy)
- 정밀도 (Precision)
- 재현율 (Recall)
- F1-Score
- ROC Curve 및 AUC
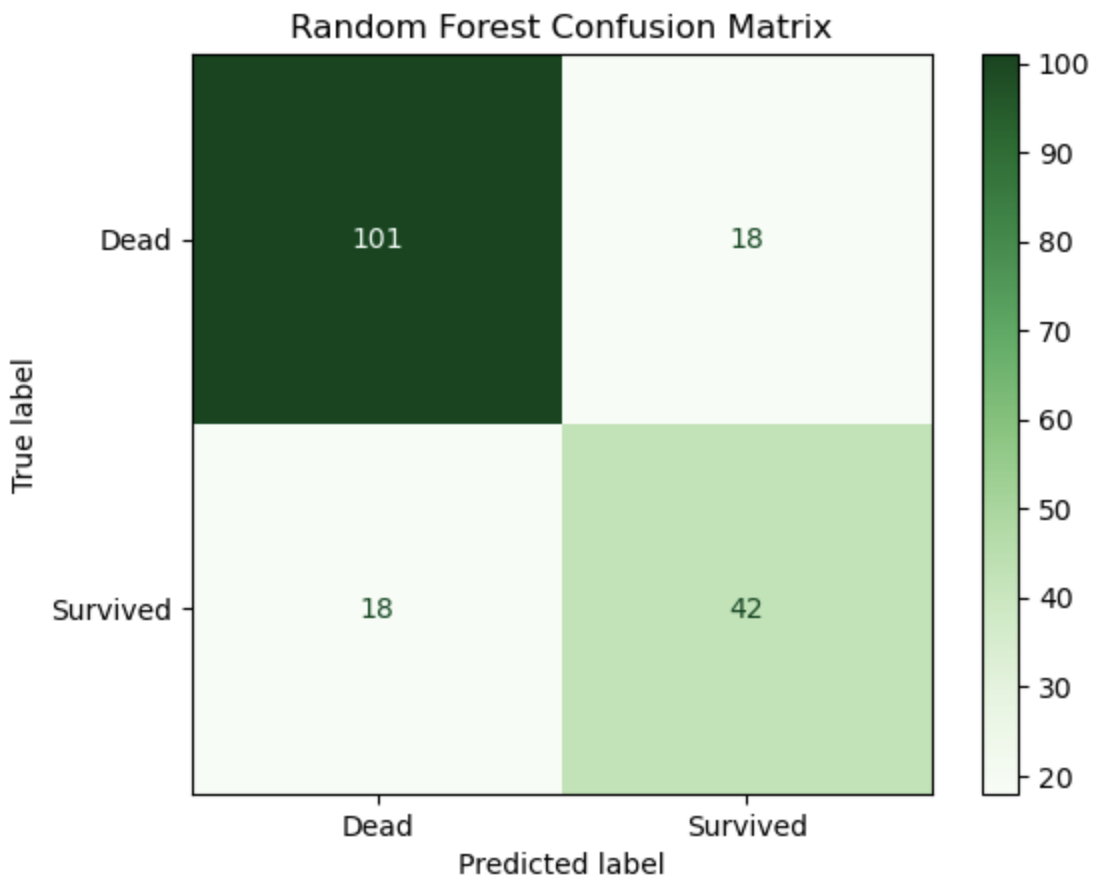
- Confusion Matrix
- 결과 해석: 모델의 예측 성능을 분석하고, 어떤 피처가 생존에 유의미한 영향을 미치는지 인사이트를 도출합니다.
개발 임팩트: Logistic Regression 모델의 기본 개념과 실제 적용 과정을 익힘으로써, 향후 다양한 이진 분류(binary classification) 문제에 대한 모델링 역량을 강화할 수 있습니다. 데이터 전처리 및 피처 엔지니어링의 중요성을 이해하고 실무에 적용하는 데 도움을 줍니다.
커뮤니티 반응: (콘텐츠 자체에 특정 커뮤니티 반응이 언급되지 않았습니다.)
톤앤매너: 객관적이고 설명적인 톤으로, 데이터 분석 및 머신러닝 입문자들이 쉽게 이해할 수 있도록 구성되어 있습니다.
📚 관련 자료
titanic
타이타닉 생존자 예측 Kaggle 경진대회 솔루션을 제공하는 GitHub 저장소입니다. 데이터 전처리, 피처 엔지니어링, 다양한 머신러닝 모델(Logistic Regression 포함) 구현 및 평가 과정을 참고할 수 있습니다.
관련도: 95%
learn-machine-learning
머신러닝 학습을 위한 포괄적인 로드맵과 예제 코드를 제공하는 저장소입니다. Logistic Regression을 포함한 다양한 기본 알고리즘에 대한 이론적 설명과 Python 구현을 찾아볼 수 있어, 본 콘텐츠의 내용을 심화 학습하는 데 유용합니다.
관련도: 80%
scikit-learn
Python의 대표적인 머신러닝 라이브러리인 scikit-learn의 공식 GitHub 저장소입니다. Logistic Regression 모델을 포함한 다양한 분류, 회귀, 클러스터링 알고리즘의 구현과 사용법에 대한 방대한 문서를 제공하여, 코드의 세부적인 이해를 돕습니다.
관련도: 75%