UNIST, 데이터 정렬 없는 AI 멀티모달 학습 기술 개발 - '와서스테인 거리' 활용
🤖 AI 추천
AI 모델 학습의 효율성 및 비용 절감에 관심 있는 AI 연구원, 머신러닝 엔지니어, 데이터 과학자에게 유용한 정보입니다. 특히 멀티모달 데이터 처리의 어려움을 겪고 있거나 새로운 학습 방법을 탐색하는 개발자에게 추천합니다.
🔖 주요 키워드
-
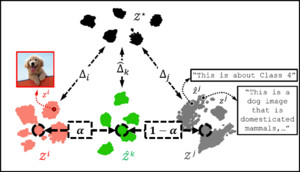
핵심 기술: UNIST 연구팀은 데이터 정렬 및 라벨링 없이도 다양한 모달리티(텍스트, 이미지, 오디오 등)의 AI 모델 학습을 상호 촉진할 수 있는 혁신적인 멀티모달 학습 기술을 개발했습니다.
-
기술적 세부사항:
- 기존 멀티모달 학습은 데이터 정렬 및 쌍별 라벨링에 시간과 비용이 많이 소모되고, 데이터 부족 시 성능 저하가 발생하는 문제점을 안고 있었습니다.
- 연구팀은 두 확률 분포 간 거리 측정 지표인 '와서스테인 거리(Wasserstein Distance)'를 활용하여, 서로 다른 모달리티 모델 간의 정보 거리를 측정하고 이론적으로 학습 촉진 가능성을 증명했습니다.
-
실험 결과, 정렬되지 않은 언어-이미지, 이미지-오디오, 언어-오디오 조합에서도 단일 모달리티 학습 대비 성능 향상을 확인했습니다.
-
개발 임팩트:
- 의료, 자율주행, AI 비서 등 정렬된 데이터셋 확보가 어려운 분야에서 개발 비용 및 시간 절감이 가능합니다.
- 음성 및 표정 분석을 통한 감정 이해 AI, CT 영상과 진료 기록 결합 진단 의료 AI 등 실제 서비스 구현에 기여할 수 있습니다.
-
기존 멀티모달 학습 방식에 대한 고정관념을 깨는 새로운 접근 방식입니다.
-
커뮤니티 반응: (제시된 내용에 커뮤니티 반응 언급 없음)
-
톤앤매너: UNIST 연구팀의 혁신적인 기술 개발 성과를 소개하며, 핵심 기술 원리 및 실제 적용 가능성을 명확하게 전달합니다.
📚 관련 자료
PyTorch-Geometric
PyTorch Geometric은 그래프 신경망(GNN) 및 기하학적 딥러닝을 위한 라이브러리로, 다양한 데이터 모달리티를 텐서 형태로 표현하고 처리하는 데 필요한 기본적인 도구를 제공하여 멀티모달 학습 연구에 활용될 수 있습니다.
관련도: 85%
OpenAI CLIP
CLIP(Contrastive Language–Image Pre-training)은 텍스트와 이미지를 함께 학습하여 자연어 지침으로 이미지를 분류하는 모델입니다. 이는 UNIST의 언어-이미지 멀티모달 학습 연구와 유사한 개념을 다루며, 정렬되지 않은 데이터로 학습하는 방식에 대한 아이디어를 얻을 수 있습니다.
관련도: 90%
Torchaudio
Torchaudio는 PyTorch를 위한 오디오 처리 라이브러리로, 오디오 데이터를 로드, 처리 및 분석하는 데 필요한 다양한 기능을 제공합니다. 이미지, 텍스트와 함께 오디오 데이터를 다루는 멀티모달 학습 실험에서 필수적인 역할을 할 수 있습니다.
관련도: 75%