vLLM: LLM 서빙의 표준 프레임워크, Paged Attention을 통한 혁신적인 메모리 관리 기법 분석
🤖 AI 추천
LLM 서빙 시스템 구축 및 최적화에 관심 있는 백엔드 개발자, ML 엔지니어, DevOps 엔지니어.
🔖 주요 키워드
핵심 기술: vLLM은 LLM 인퍼런스 프레임워크로서, 대규모 언어 모델(LLM)의 효율적인 서빙을 위해 Paged Attention이라는 혁신적인 KV Cache 메모리 관리 기법을 도입했습니다. 이는 기존의 메모리 할당 방식에서 발생하는 단편화 문제를 해결하고 GPU 활용률을 극대화하여 처리량을 향상시킵니다.
기술적 세부사항:
- LLM 인퍼런스의 문제점:
- 요청 도착 시점 및 길이 예측 불가로 인한 배치 대기 시간 및 비효율.
- 다양한 길이의 요청 처리 시 발생하는 패딩으로 인한 메모리 낭비.
- KV Cache로 인한 GPU 메모리 관리의 복잡성 및 메모리 바운드 특성.
- 디코딩 알고리즘(무작위 샘플링, Beam Search)에 따른 KV Cache 공유의 어려움.
- 출력 길이 예측 불가로 인한 동적 KV Cache 할당의 어려움.
- Paged Attention 메커니즘:
- 운영체제의 페이징 기법에서 영감을 받아, KV Cache를 고정된 크기의 블록으로 분할하고 비연속적인 공간에 할당.
- 각 시퀀스를 논리적 KV 블록으로 분할하고, 물리적 GPU 블록에 매핑.
- Block Table을 통해 논리적 블록과 물리적 블록 간의 매핑 관리.
- Attention 연산 역시 블록 단위로 독립적으로 수행 가능.
- Paged Attention 활용 방안:
- 디코딩 단계: 초기 프롬프트 처리 시 최소한의 블록만 할당하고, 토큰 생성 시 동적으로 블록 할당.
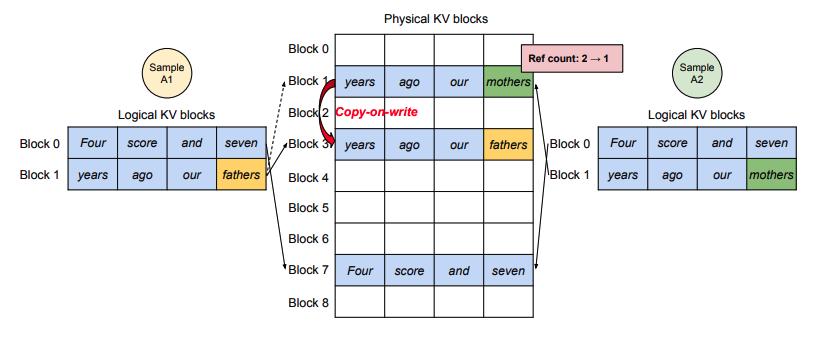
- Parallel Sampling: Copy-on-Write(COW) 기법을 활용하여 여러 시퀀스가 동일한 물리적 블록을 공유.
- Beam Search: 각 후보 시퀀스가 KV Cache 블록을 공유하며, 유망하지 않은 블록은 제거.
- Shared Prefix (System Prompt): 자주 사용되는 시스템 프롬프트를 Prefix Cache로 저장하고, COW를 통해 효율적으로 공유.
- 스케줄링 및 캐시 관리:
- 기본적으로 FCFS (First-Come, First-Served) 스케줄링.
- All-or-Nothing Eviction: 시퀀스의 모든 블록이 함께 제거되거나 유지.
- Cache 복구: Swapping (CPU 메모리로 이동) 및 Recomputation (재계산) 기법 활용.
- 확장성: Pipeline Parallelism 및 Tensor Parallelism 지원.
개발 임팩트:
- GPU 메모리 활용률 극대화를 통한 처리량 (Throughput) 향상.
- 동적이고 효율적인 KV Cache 관리를 통한 응답 시간 (Latency) 감소.
- 더 많은 요청을 효율적으로 처리하여 비용 절감 및 서비스 확장성 증대.
- LLM 서빙 시스템의 안정성과 성능 최적화에 기여.
커뮤니티 반응:
vLLM은 LLM 인퍼런스 분야에서 사실상의 표준으로 자리 잡고 있으며, 많은 연구기관과 기업에서 LLM 서빙 엔진으로 채택하고 있습니다. 오픈소스 커뮤니티의 높은 관심과 기여를 받고 있습니다.
📚 관련 자료
vLLM
LLM 서빙을 위한 고성능 추론 엔진으로, Paged Attention을 포함한 혁신적인 메모리 관리 및 스케줄링 기법을 구현한 공식 저장소입니다.
관련도: 100%
FastTransformer
NVIDIA에서 개발한 트랜스포머 모델 가속 라이브러리로, vLLM의 성능 비교군으로 자주 언급되며 LLM 인퍼런스 최적화에 대한 다양한 기법들을 포함하고 있습니다.
관련도: 70%
Hugging Face Transformers
다양한 LLM 모델의 로딩, 학습, 추론을 지원하는 라이브러리로, vLLM과 같은 서빙 프레임워크와 함께 사용되어 LLM 기반 애플리케이션 개발의 기반이 됩니다.
관련도: 60%