인공지능 에이전트의 작동 원리
카테고리
인공지능
서브카테고리
데이터 분석
대상자
- 데이터 과학자, 머신러닝 엔지니어, 소프트웨어 개발자
- 난이도 높은 기술적 내용 포함 (데이터 파이프라인, 머신러닝 모델, MLOps 등)
핵심 요약
- 인공지능 에이전트는 "수집-처리-결정-피드백"의 반복 사이클을 통해 작동
- 대규모 데이터 수집을 위해 Apache Kafka, Apache Spark 등 강력한 프레임워크 사용
- ETL 파이프라인과 특성 공학을 통해 원시 데이터를 모델에 적합한 형식으로 변환
- MLOps를 통해 모델 재학습, 조정, 배포 프로세스 자동화
섹션별 세부 요약
1. 데이터 수집 및 전처리
- 사용자 행동, 인구통계, 콘텐츠 특성, 세션 컨텍스트 데이터 수집
- Apache Kafka로 초당 수백만 건의 이벤트 실시간 수집
- Apache Spark로 분산 처리 및 실시간/배치 분석 수행
2. 데이터 처리 및 특성 공학
- ETL 파이프라인을 통해 데이터 정제, 정규화, 집계
- 사용자 선호도, 시청 시간 평균 등 의미 있는 특성 추출
- 데이터 품질 보장을 위한 누락 값 처리, 중복 제거, 형식 표준화
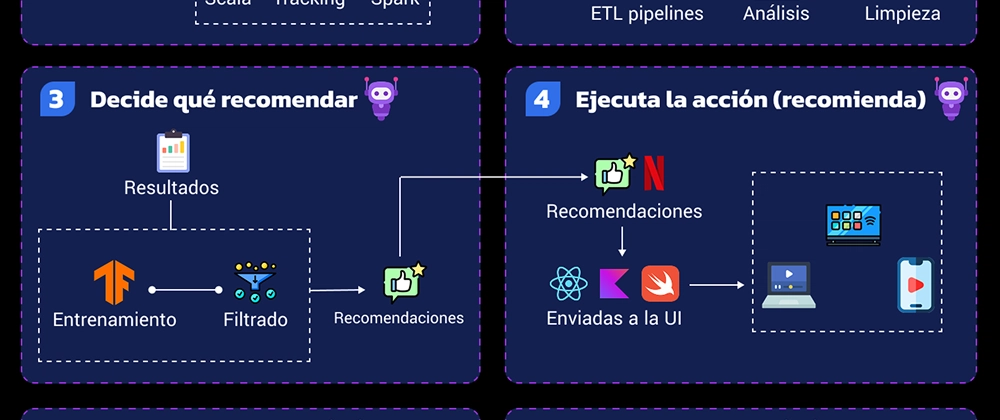
3. 모델 학습 및 추천 알고리즘
- 협업 필터링, 콘텐츠 기반 필터링, 딥러닝 모델 등 다양한 추천 기법 적용
- 사용자-아이템 잠재 공간 학습을 위한 복잡한 신경망 구조 사용
- 모델 학습 후, 사용자에게 맞춤형 추천 목록 생성 및 랭킹 정렬
4. 피드백 및 모델 개선
- 사용자 클릭, 재생 시간, 평가 등 피드백 데이터 실시간 수집
- A/B 테스트를 통해 새로운 알고리즘 효과 평가
- MLOps를 통해 모델 재학습, 하이퍼파라미터 최적화, 배포 자동화
5. UI 연동 및 사용자 경험 최적화
- 추천 목록을 스마트폰, TV 등 다양한 플랫폼의 UI에 전달
- 카로셀, 섹션, 알림 등 사용자 경험을 고려한 디스플레이 방식 적용
- 사용자 행동 분석을 통해 추천 알고리즘 지속적으로 조정
결론
- AI 에이전트는 데이터 수집, 처리, 학습, 피드백의 반복 사이클을 통해 지능을 발휘
- MLOps 도입으로 모델 업데이트 프로세스 자동화 및 효율성 극대화
- 사용자 행동 데이터를 실시간 분석해 개인화 추천을 제공하는 것이 핵심