AI 기반 실시간 원인 분석 시스템 구축 기술 심층 분석
카테고리
프로그래밍/소프트웨어 개발
서브카테고리
인공지능, 머신러닝
대상자
AI/ML 엔지니어, 데이터 과학자, DevOps 개발자
- 난이도: 중급~고급 (구체적인 기술 스택과 아키텍처 구현 설명 포함)
핵심 요약
Retrieval-Augmented Generation (RAG)기반의 동적 컨텍스트 인식 분석으로 LLM의 사전 지식 의존도 최소화LangChain's BufferMemory사용으로 2000-token 슬라이딩 윈도우 기반 대화 흐름 관리Web Worker기반 비동기 데이터 처리로 UI 응답성 향상
섹션별 세부 요약
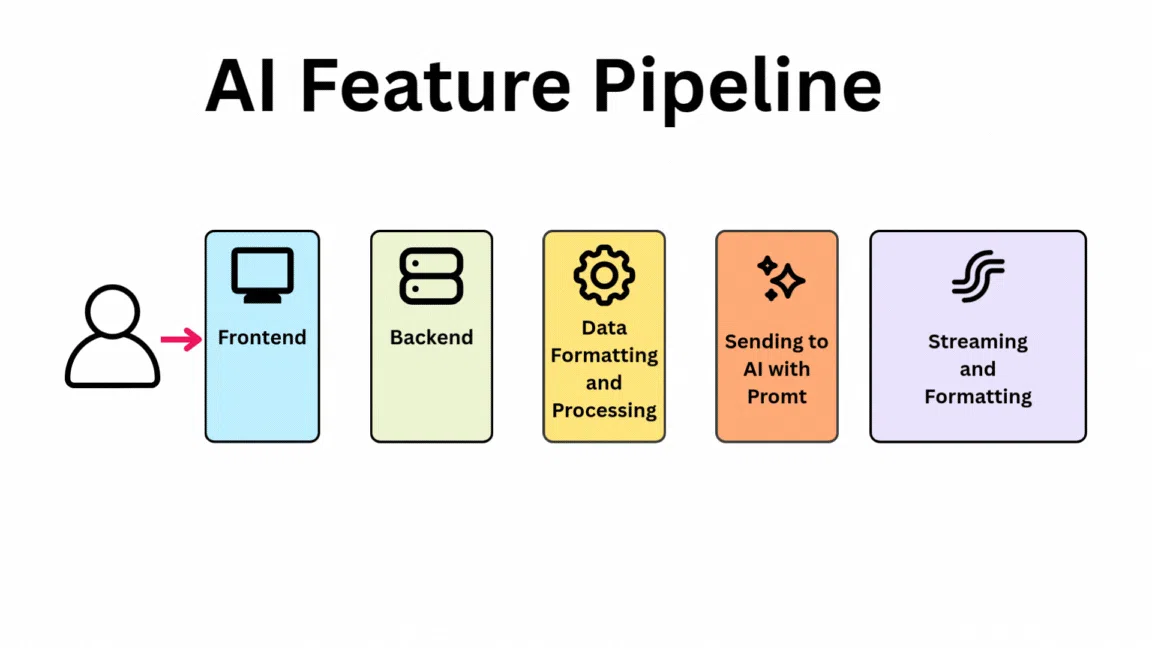
1. RAG 기반 분석 시스템 설계
- RAG 파이프라인을 통해 실시간 데이터 소스 연동으로 LLM의 hallucination 감소
- 사전 지식 대신 최신 데이터 기반의 분석 결과 생성
- 검색 결과와 생성 결과의 정확도 검증 레이어 구현
2. 대화 흐름 관리
LangChain's BufferMemory활용으로 다중 턴 대화의 문맥 유지- 2000-token 범위 내에서 대화 기록 자동 유지
- 사용자 세션 내 연속적인 질의-응답 처리 가능
3. 비동기 데이터 처리
Web Worker를 통해 데이터 전처리, 트래픽 메트릭 계산, 캠페인 집계 등의 병목 처리- UI 스레드와 분리된 별도 스레드 실행
formatProductData.worker.js스크립트 기반의 클라이언트 측 계산 처리
4. 실시간 토큰 스트리밍
LangChain의 콜백 아키텍처를 활용한 토큰 단위 실시간 출력- LLM 응답 생성 중 즉시 UI에 텍스트 렌더링
- 사용자 피드백 시간 단축을 위한 핵심 기능
5. 텍스트 렌더링 엔진
- TipTap 헤드리스 에디터 프레임워크를 통한 Markdown, 코드 블록, 테이블 등 다양한 포맷 지원
- 채팅 인터페이스 내 풍부한 텍스트 형식 렌더링
6. API 요청 관리
- 1초 간격의 요청 제한(Limiter)으로 LLM API 과부하 방지
- 큐 기반 요청 처리 시스템으로 동시 요청 처리 최적화
7. 캐싱 전략
- 메모리 기반 캐싱 시스템 구현으로 반복 요청 시 처리 시간 절감
- 이전 분석 결과 재사용을 통한 성능 향상
8. 오류 처리
- 비동기 작업 전반에 걸친 fail-safe 레이어 적용
- 오류 발생 시 사용자 친화적 메시지 및 대체 처리 기능 구현
결론
- RAG + Web Worker + LangChain의 조합으로 실시간 분석 시스템 구축 가능
- 데이터 분할, 캐싱, 요청 제한을 통해 시스템 안정성과 성능 균형 확보
- TipTap과 실시간 토큰 스트리밍을 통해 사용자 경험 개선 효과
- 모든 비동기 작업에 fail-safe 레이어 적용이 안정적인 시스템 운영의 핵심 요소