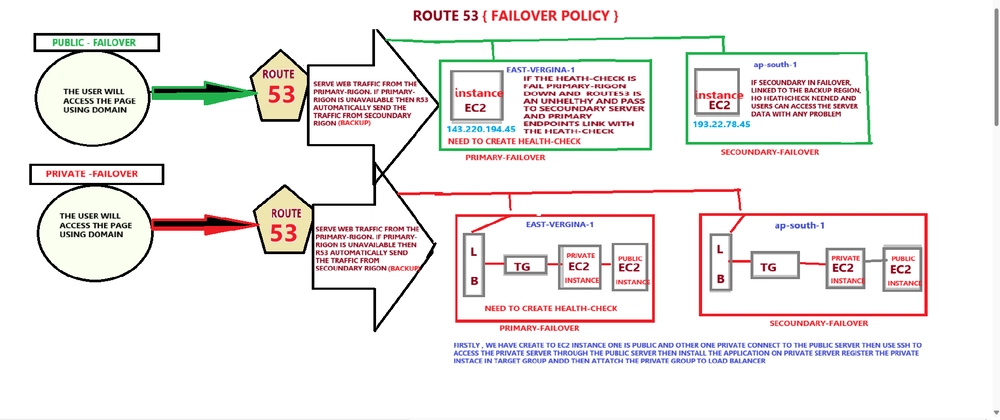
AWS Route 53의 Failover 정책을 통한 고가용성 설계
카테고리
인프라/DevOps/보안
서브카테고리
DNS
대상자
- 대상자: DevOps 엔지니어, 시스템 설계자, 클라우드 아키텍터
- 난이도: 중급~고급 (AWS DNS 서비스 및 고가용성 아키텍처 이해 필요)
핵심 요약
- AWS Route 53 Failover 정책은 DNS 기반의 자동 장애 복구(Failover)를 통해 99.99% 이상의 서비스 가용성 보장
- Health Check 기능을 통해 서버/리소스 상태 실시간 모니터링 후 자동 DNS 라우팅 변경
- Failover 정책은 AWS EC2, ELB, S3 등 클라우드 리소스와 호환 가능하며 지리적 분산(Multi-Region) 지원
섹션별 세부 요약
1. Failover 정책의 핵심 원리
- Health Check 설정: TCP/HTTP/HTTPS 프로토콜 기반으로 리소스 상태 확인
- Failover 트리거 조건: 3회 이상의 연속 실패 시 DNS 레코드 자동 변경
- Failback 기능: 장애 원인 해소 시 원래 리소스로 자동 복귀
2. 실무 적용 사례
- Multi-Region 아키텍처: 아프리카/아시아/유럽 서버 그룹 간 지리적 라우팅
- EC2 Auto Scaling과 연동: 장애 발생 시 자동으로 스케일아웃 리소스로 트래픽 전환
- AWS CloudWatch와 연동: Health Check 메트릭을 실시간으로 모니터링 및 알림
3. 고려사항 및 최적화 팁
- Failover 지연 시간 최소화를 위해 Health Check 간격(10-30초)과 타임아웃(5-10초) 조정
- DNS TTL(Time to Live) 설정: 짧은 TTL(30-60초)으로 빠른 라우팅 업데이트
- Failover 정책과 Route 53 Latency-based Routing 병행 시 지리적 성능 최적화
결론
- Failover 정책을 적용할 때는 Health Check 설정의 정확성과 DNS TTL 최적화가 핵심
- AWS CloudFormation 또는 Terraform을 통해 자동화된 인프라 구성 권장
- 정기적인 테스트(예:
dig,nslookup명령어)로 Failover 동작 검증 필수