화웨이, 자체 '어센드' 칩에 최적화된 MoE 모델 출시..."딥시크-R1 능가"
카테고리
프로그래밍/소프트웨어 개발
서브카테고리
인공지능, 머신러닝
대상자 대상자_정보
- AI 연구자, 대규모 언어모델(LLM) 개발자, 하드웨어 최적화 엔지니어
- 난이도: 고급(기술적 세부 사항 및 성능 지표 포함)
핵심 요약
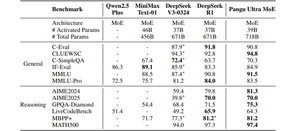
_판구 울트라 MoE(Pangu Ultra MoE)_모델은 7180억 개의 매개변수를 갖는 희소(Sparse) 대형언어모델로, 어센드 NPU에 최적화된 MoE(혼합 전문가)** 구조를 채택했다.- 5가지 병렬화 기법(파이프라인, 텐서, 전문가, 데이터, 컨텍스트)을 활용해 256개 전문가, 7680 히든 스테이트, 61 레이어 구조를 최적화했다.
- AIME 2024(81.3%), MATH500(97.4%) 등 벤치마크에서 딥시크-R1을 초과하는 성능 달성.
섹션별 세부 요약
- *1. 모델 개요**
- Pangu Ultra MoE는 7180억 매개변수를 갖는 희소 모델로, 쿼리에 따라 일부 전문가 모델만 활성화하는 동적 구조를 채택.
- 어센드 NPU에 맞춤 설계되어, 하드웨어-소프트웨어 시너지를 강조.
- *2. 최적화 기법**
- 5가지 병렬화 기법(파이프라인, 텐서, 전문가, 데이터, 컨텍스트)을 활용한 대규모 시뮬레이션을 통해 최적 구조 도출.
- NPU 간 통신 최적화로 동기화 오버헤드 감소 및 메모리 부하 분산 기술 적용.
- *3. 성능 지표**
- 6000개 어센드 NPU 사용 시 30.0% MFU(모델 플롭 활용도) 달성, 초당 146만 토큰 처리 성능.
- AIME 2024(81.3%), MATH500(97.4%), CLUEWSC(94.8%), MMLU(91.5%) 등 딥시크-R1 초과 성능 보여.
- *4. 협력 및 전략**
- 아이플라이텍과 협력해 어센드 칩으로만 훈련된 모델(싱훠 X1) 출시.
- 딥시크-R2 학습에 참여한 것으로 알려져, 경쟁사 기술 끌어올리기 전략 강조.
- *5. 연구 의미**
- MoE 모델 학습의 가능성을 실증, 어센드 시스템이 LLM 모든 학습 단계에 활용 가능하다는 결론.
결론
- 하드웨어-소프트웨어 최적화가 핵심이며, NPU 병렬화 기법과 모델 아키텍처 조합이 성능 향상에 기여.
- 경쟁사 기술 의존도 감소와 자체 AI 기술 경쟁력 강화를 위한 전략적 성과로 평가.