"챗GPT보다 싸고 빠르다"…라이너, 검색 LLM으로 AI 검색 시장 '정조준'
카테고리
프로그래밍/소프트웨어 개발
서브카테고리
인공지능
대상자
- 프로젝트 개발자, AI 모델 엔지니어, 데이터 과학자
- 중급~고급 수준의 AI 성능 최적화 및 비용 효율성 분석에 관심 있는 개발자
핵심 요약
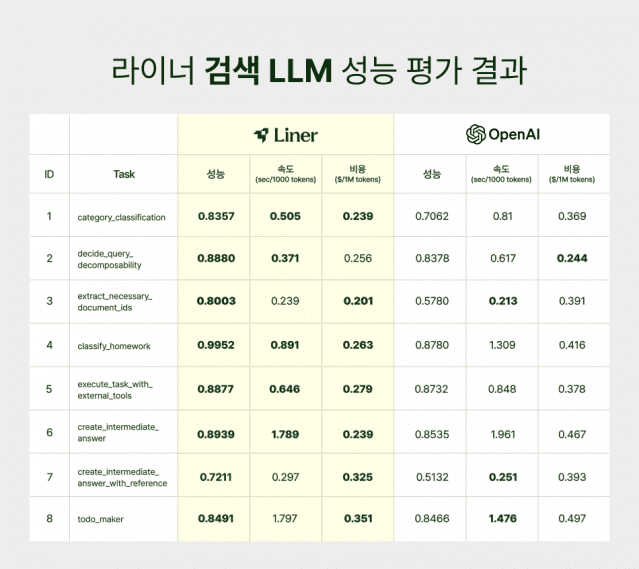
- 라이너 검색 LLM은 GPT-4.1 대비 토큰당 비용 30~50% 절감 및 정확도·속도 향상 성능을 달성
- 8개 컴포넌트 통합 구조로 질문 분석부터 답변 생성까지 검색형 에이전트 전 과정 처리
- 실제 서비스 환경 기반 성능 검증으로 할루시네이션 감소 및 신뢰성 향상
섹션별 세부 요약
1. 모델 성능 비교
- 라이너 검색 LLM이 GPT-4.1 대비 카테고리 분류, 과제 분류, 외부 도구 실행, 중간 답변 생성 등 4개 컴포넌트에서 성능·속도·비용 전 항목 우수
- 토큰당 비용 절감을 통해 AI 검색 시장의 경쟁력 확보
- 방대한 사용자 데이터 기반 사후 학습으로 정확도 향상
2. 모델 구조 및 학습 방식
- 8개 컴포넌트 통합 구조로 검색형 에이전트의 전 과정 처리
- 자사 사용자 데이터 활용한 정밀 학습으로 질문 처리 구조 체계화
- 할루시네이션 가능성 줄이기 위한 학습 구조 고도화
3. 실사용 기반 성능 검증
- 실제 서비스 환경에서 재현성과 신뢰성 기반 성능 측정
- 단순 벤치마크 수치가 아닌 실사용 데이터 중심으로 비용·속도·정확도 균형 검증
- 기존 대형 모델 대비 가볍고 빠른 검색형 LLM 구현 가능
4. 모델 개발 및 테스트 역량
- 수년간 테스트와 개선 반복으로 LLM 학습 구조 고도화
- 실제 서비스 환경 기반의 지속적 성능 개선
- AI 검색 시장의 차별화된 경쟁력 확보
결론
- 자사 사용자 데이터 기반의 정밀 학습과 실사용 기반 성능 검증을 통해 AI 검색 모델의 경쟁력 확보
- 검색형 LLM 구현 시 실제 서비스 환경에 맞춘 데이터 기반 학습과 성능 측정을 중점적으로 고려해야 함