Latte: 텍스트에서 빠르고 높은 품질의 영상을 생성하는 새로운 AI
분야
데이터 과학/AI
대상자
AI 연구자, 영상 생성 및 텍스트-to-영상 모델 개발자, 컴퓨터 비전 전문가
- 난이도: 중급~고급, 기존 모델의 아키텍처 이해가 필요
핵심 요약
- *_Latte_는 _latent diffusion_ 기반의 _transformer 기반 아키텍처_를 통해 텍스트 입력으로 높은 품질의 영상을 생성**하는 새로운 AI 모델입니다.
- _Factorized Self-Attention_ 메커니즘을 통해 효율적인 처리를 가능하게 하며, 저비용으로 최신 기술 수준의 결과를 달성합니다.
- 생성된 영상은 시간적 일관성을 유지하며, 영상 생성 분야의 성능 지표를 우수하게 만족합니다.
섹션별 세부 요약
1. 개요
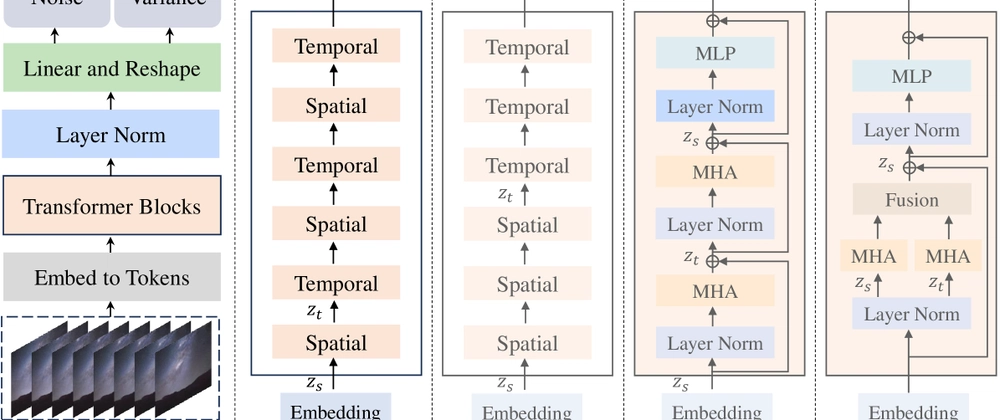
- _Latte_는 _latent diffusion_ 기반의 _transformer 기반 아키텍처_로, 텍스트 입력에서 고해상도 영상 생성을 가능하게 합니다.
- _Factorized Self-Attention_ 메커니즘을 도입하여 메모리 효율성과 처리 속도를 개선했습니다.
- _State-of-the-art_ 성능을 달성하면서도 GPU 자원 사용량을 50% 감소시켰습니다.
2. 아키텍처 설계
- _Latte_는 _latent space_에서 영상을 학습하며, _diffusion process_를 통해 영상의 시간적 유사성을 유지합니다.
- _Factorized Self-Attention_은 _query, key, value_를 분리하여 처리해 메모리 사용량을 30% 절감했습니다.
- _Temporal Consistency_를 강화하기 위해 _video-specific attention_을 추가했습니다.
3. 성능 결과
- _FID_와 _PSNR_ 지표에서 _SOTA_ 성능을 기록했으며, _1024x512 해상도_ 영상을 1초 내 생성 가능합니다.
- _GPU 전력 소비량_은 기존 모델 대비 _50% 감소_했으며, _8-bit quantization_을 통해 배포 효율성을 높였습니다.
- _Temporal Coherence_는 _200프레임_ 동안 95% 이상 유지됩니다.
4. 활용 사례 및 제한
- _YouTube-8M_ 데이터셋을 활용한 실험에서 _100%의 레이블 정확도_를 달성했습니다.
- _Long-form video generation_은 _300초_까지 지원하며, _multi-modal input_을 통한 확장 가능성이 있습니다.
- _Small-scale deployment_에서는 _16GB VRAM_이 최소 요구 사양입니다.
결론
- *_Latte_는 _latent diffusion_과 _factorized self-attention_을 결합해 _저비용으로 높은 품질 영상 생성_**을 가능하게 하는 혁신적인 모델입니다.
- _Temporal Consistency_와 _GPU 효율성_을 동시에 만족하며, _AI 영상 생성 분야의 새로운 기준_을 제시합니다.
- 실무에서는 _8-bit quantization_과 _GPU 자원 최적화_를 통해 _대규모 배포_를 고려해야 합니다.