AI 안전 문제로 지적받은 오픈AI, '안전성 평가' 수시 공개..."구글·메타도 문제" 지적
카테고리
데이터 과학/AI
서브카테고리
인공지능, 머신러닝
대상자
AI 모델 개발자, 안전성 평가 담당자, AI 기술 정책 담당자
핵심 요약
- OpenAI는 '안전 평가 허브'를 통해 GPT-4o, o3, o4-미니 등 주요 모델의 안정성 평가 결과를 수시 업데이트
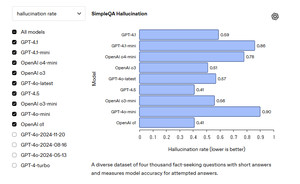
- GPT-4.5는 환각 테스트에서 가장 강한 성능을 보였으나, 사전 훈련 비용에 비해 성능 향상이 미미
- 구글과 메타는 AI 연구 부서의 우선순위를 상품 개발 부서보다 낮추며, 안전성 평가를 소홀히 함
섹션별 세부 요약
1. OpenAI의 안전 평가 허브 발표
- OpenAI는 GPT-4o, o3, o4-미니 등 9개 주요 모델의 안정성 평가 결과를 공개
- 평가 항목: 유해한 콘텐츠, 탈옥, 환각, 지침 계층 구조
- o3 모델은 대부분의 안정성 지표에서 가장 우수한 성능을 보임
2. GPT-4.1의 안정성 평가
- GPT-4.1은 탈옥 벤치마크에서 취약하지만, 인간의 탈옥 시도 및 환각 테스트에서는 강한 성능
- 이전에 기술 보고서 공개 거부로 알려진 모델
3. GPT-4.5의 평가 결과
- GPT-4.5는 환각 테스트에서 최고 성능을 보였으나, 사전 훈련 비용에 비해 성능 향상 미미
- 이 모델은 이미 ChatGPT에서 서비스 중단됨
4. OpenAI의 안전 평가 정책 변화
- OpenAI는 기존 시스템 카드 기반 평가에서 '안전 평가 허브'로 전환
- 안전성 평가를 제품 개발보다 우선시하는 방향으로 정책 변화
5. 구글과 메타의 AI 연구 부서 문제
- 구글은 Gemini 2.5 발표 시 모델 카드 공개 미비로 비난
- 메타는 FAIR 연구 부서의 우선순위가 MetaGenAI 제품 부서보다 낮음
- 조엘 피노 책임자는 FAIR 이끌며 사퇴 의사를 밝힘
결론
- AI 모델의 안전성 평가는 기술적 성능과 동등한 중요도를 가져야 함
- OpenAI는 '안전 평가 허브'를 통해 모델의 안정성을 수시 공개하는 방향으로 전환
- 구글과 메타는 AI 연구 부서의 우선순위를 재조정해야 하며, 모델 카드 및 위험성 평가 공개를 강화해야 함