Conversando com seu Repositório: Um Projeto Prático com RAG e LLMs Locais
카테고리
- *프로그래밍/소프트웨어 개발**
서브카테고리
- *인공지능**
대상자
- 개발자 및 데이터 과학자
- LLM, RAG, 벡터 데이터베이스 기술 적용에 관심 있는 사람
- 난이도: 중간 이상 (AI 개념, Python, 라이브러리 사용 이해 필요)
핵심 요약
- RAG 아키텍처는
LLM과벡터 데이터베이스를 결합해 코드 저장소에서 질문에 대한 정확한 답변을 생성합니다. - 로컬 실행으로 인해 API 키 및 인터넷 연결 없이 100% 프라이버시 보장이 가능합니다.
- Gemma:2B와 같은 로컬 LLM 모델 사용을 통해 코드 분석 및 질의 응답을 처리합니다.
섹션별 세부 요약
1. **RAG 아키텍처의 3단계**
- Vector Store (벡터 저장소):
- 코드 저장소의 모든 파일을 chunks로 분할하고, embedding 모델을 사용해 벡터로 변환하여 저장.
- 예: sentence-transformers 라이브러리 활용.
- Retriever (검색기):
- 질문을 벡터로 변환하여 벡터 저장소에서 유사도 기반으로 관련 문서를 검색.
- Self-QueryRetriever 사용 시 메타데이터 필터링으로 검색 속도 및 정확도 향상.
- LLM (언어 모델):
- 검색된 문서와 질문을 조합하여 Gemma:2B 모델을 통해 최종 답변 생성.
- 답변 생성 시 허위 정보 생성 방지를 위해 문서 기반의 맥락 제공.
2. **프로젝트 구축 준비 작업**
- 환경 설정:
- Python 3.8 이상, 가상 환경(venv) 생성.
- ollama 설치 및 gemma:2b 모델 다운로드.
- 의존성 관리:
- requirements.txt 파일에 langchain, chromadb, sentence-transformers 등 라이브러리 포함.
- pip install -r requirements.txt 명령어로 설치.
3. **데이터 처리 및 저장소 구성**
- config.py:
- REPO_PATH 변수로 코드 저장소 경로 설정.
- data_loader.py:
- YamlProcessor, SqlProcessor 등 클래스로 파일 별 구조화된 정보 추출.
- page_content와 metadata 정의:
- page_content: 문서의 실제 텍스트 (예: "dag_exemplo"의 소유자: 'ana.silva').
- metadata: dag_id, table_name 등 검색 필터링을 위한 메타데이터.
- vector_store.py:
- ChromaDB를 사용한 벡터 저장소 생성 및 관리.
- indexer.py:
- 저장소 인덱싱 작업 수행.
- 예: python indexer.py 명령어로 실행.
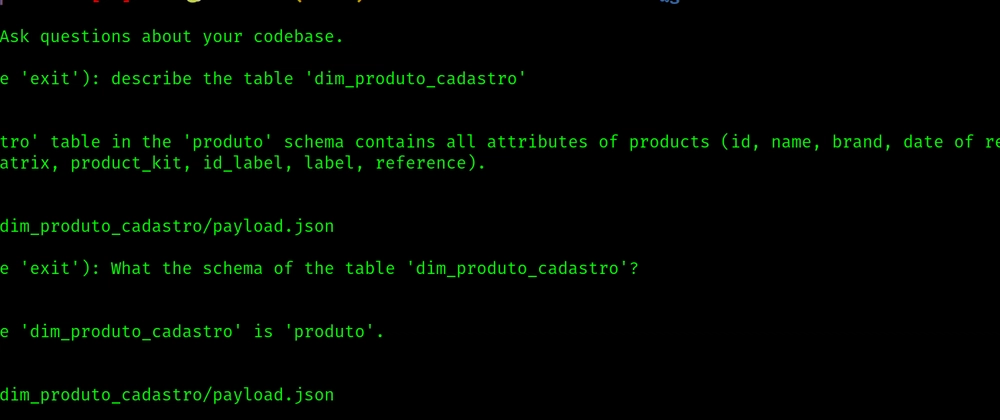
4. **질의응답 툴 사용 예시**
- 예제 1:
- 질문: "dag 'process_seller_data_dag'의 소유자는 누구인가?"
- 답변: "ana.silva@suaempresa.com"
- 출처: ./data/dags/process_seller_data_dag/dag.yaml
- 예제 2:
- 질문: "analytics_prod.seller_reputation' 테이블을 사용하는 SQL 쿼리는?"
- 답변: SELECT ... FROM analytics_prod.seller_reputation WHERE ...
- 활용 예: 성능 모니터링 대시보드, 데이터 분석 등.
결론
- 로컬 실행 및 프라이버시 보장을 위해
ollama와ChromaDB를 활용한 RAG 시스템 구축. - Gemma:2B 모델 사용으로 인한 빠른 처리 속도와 정확한 답변 생성.
- 메타데이터 기반의 스마트 필터링을 통해 검색 효율성 극대화.
- 의존성 관리 및 모듈화 설계로 프로젝트 확장성 및 유지보수성 향상.