RAG 기반 AI 개발 가이드
카테고리
프로그래밍/소프트웨어 개발
서브카테고리
인공지능
대상자
- 대상자: AI 개발자, 데이터 과학자, 자연어 처리(NLP) 엔지니어
- 난이도: 중급~고급 (Python 및 LangChain, FAISS 기술 요구)
핵심 요약
- RAG(Retrieval-Augmented Generation)는 외부 문서 기반의 정보 검색과 생성형 언어 모델을 결합하여 정확한 답변 생성을 가능하게 하는 기법입니다.
- 핵심 기술 요소:
- HuggingFaceEmbeddings("all-MiniLM-L6-v2")로 텍스트 임베딩 생성
- FAISS 벡터 데이터베이스를 사용한 유사도 검색
- LangChain을 활용한 텍스트 분할 및 처리 파이프라인
- 실무 적용 시 고려사항:
- 임베딩 모델 및 LLM 업그레이드 (예: sentence-transformers/all-mpnet-base-v2, GPT-4)
- 벡터 검색 최적화 (Pinecone, Weaviate 사용 권장)
섹션별 세부 요약
1. RAG 개요
- 정의: 생성형 모델이 내부 지식에 의존하는 대신, 외부 문서 기반의 검색을 통해 문맥에 맞는 답변 생성
- 주요 특징:
- 모델 가중치는 변경되지 않음 (외부 데이터 활용)
- 문맥 기반의 정확한 답변 생성 가능
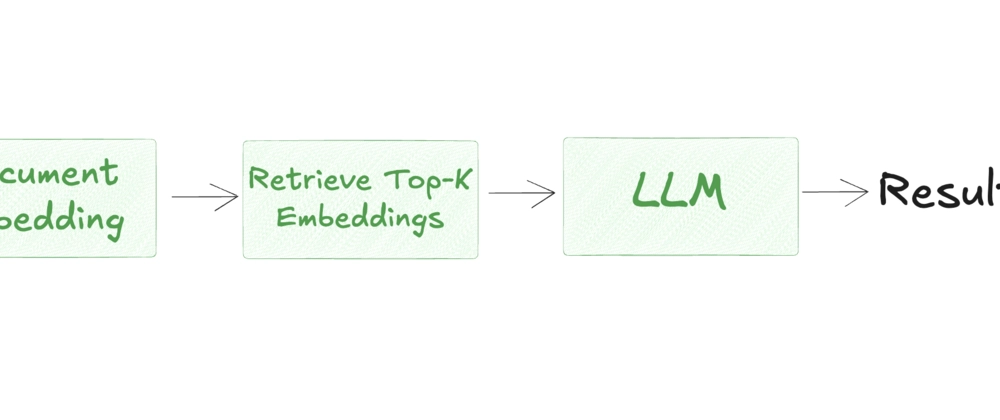
2. RAG 구축 단계
- 문서 준비: PDF, DOC 등 다양한 문서 형태의 텍스트 데이터 수집 및 전처리
- 임베딩 생성:
HuggingFaceEmbeddings로 텍스트를 임베딩 벡터로 변환 - 벡터 저장: FAISS를 활용한 임베딩 저장 및 유사도 검색 구현
- 쿼리 처리: 사용자 질문을 임베딩하여 유사한 문서 조각 검색 후 프롬프트 생성
3. 활용 사례
- 고객 지원: 제품 매뉴얼/FAQ 기반 질문 답변
- 학술 연구: 논문/기술 문서 요약
- 법률 분야: 법률 문서/규제 정보 제공
- 교육: 교과서/강의 자료 기반 질문 답변
- 기업 내 지식: 회사 문서/보고서 내 검색
4. Python 구현 예시
- 핵심 함수:
- load_text_from_pdf(): PDF 문서 텍스트 추출
- create_faiss_vectorstore(): FAISS 벡터 저장소 생성
- getChatCompletionRag(): 사용자 질문에 대한 RAG 파이프라인 실행
- 라이브러리:
- PyPDF2, LangChain, FAISS, HuggingFaceEmbeddings
5. 성능 개선 방법
- 모델 업그레이드: GPT-4, Claude 등 고성능 LLM 사용
- 임베딩 품질 향상:
sentence-transformers/all-mpnet-base-v2모델 사용 - 벡터 검색 최적화: Pinecone, Weaviate 등 확장성 있는 벡터 DB 사용
- 문맥 관리: 청크 분할/토큰 예산 관리/검색 필터링 적용
- 캐싱 전략: 반복 쿼리 시 캐싱, 인덱스 업데이트 자동화
결론
- RAG 시스템 구축 시
FAISS와HuggingFaceEmbeddings를 활용한 검색-생성 파이프라인 구현이 핵심이며, 고성능 모델 및 벡터 DB 사용을 통해 실무 적용 가능 - 모니터링 및 평가: 사용자 피드백과 출력 품질을 기반으로 지속적인 개선이 필수적