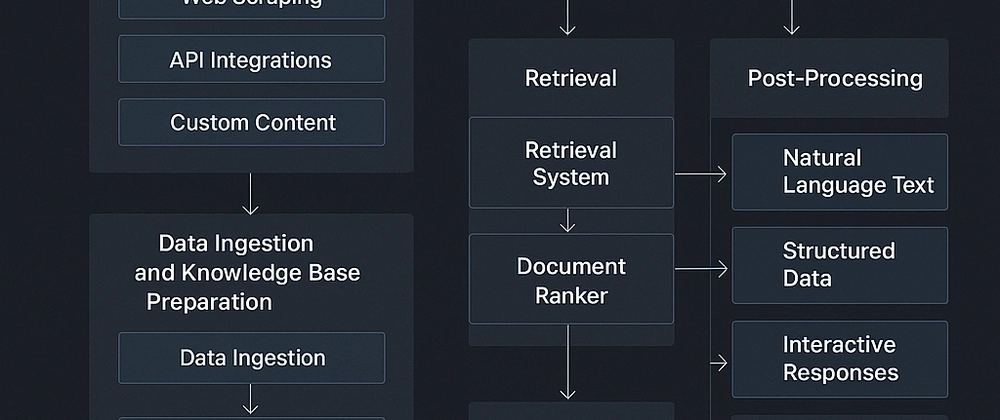
검색 강화 생성(RAG) 시스템 아키텍처 및 워크플로우
카테고리
프로그래밍/소프트웨어 개발
서브카테고리
인공지능
대상자
- 개발자, 데이터 과학자, AI 엔지니어
- 난이도: 중급 이상 (RAG 아키텍처 이해 및 구현에 필요한 기술적 지식 필요)
핵심 요약
- RAG(Retrieval-Augmented Generation)는 외부 지식 기반과 생성 모델을 결합해 실시간 데이터 검색과 맥락 기반 응답 생성을 수행하는 AI 기술
- 핵심 기술 요소: 벡터 검색(FAISS, Elasticsearch), 트랜스포머 모델(GPT-3, T5), 문서 랭킹(BM25, neural ranking)
- 주요 장점: 정확도 향상, 자동화 프로세스 최적화, 업무 효율성 증대
섹션별 세부 요약
1. 데이터 수집 및 지식 기반 준비
- 데이터 출처: 기업 내 문서, 웹 스크래핑, API 연동, 커스텀 콘텐츠
- 데이터 처리: Apache Kafka, Amazon S3, 데이터 레이크 기술 사용
- 중요성: 고질적인 데이터 품질 관리가 RAG 성능에 직접적인 영향을 미침
2. 쿼리 입력
- 입력 방식: 챗봇, 고객 서비스 포털, 검색 엔진 등에서의 사용자 쿼리
- 처리 요구사항: 모호한 쿼리에 대한 맥락 이해와 의도 분석 필요
3. 검색 메커니즘
- 검색 기법:
- 키워드 매칭: 쿼리 키워드를 기반으로 문서 검색
- 벡터 검색: 쿼리와 문서를 벡터화하여 의미 기반 검색 수행
- 문서 랭킹: BM25, TF-IDF, 신경망 기반 랭킹 모델 사용
4. 생성 메커니즘
- 생성 모델: GPT-3, T5, Huggingface 모델 활용
- 작업 내용: 검색된 문서를 기반으로 맥락 맞춤형 응답 생성, 보고서 작성, 고객 문의 답변 등
- 예시:
GPT-3를 사용한 고객 지원 자동화
5. 후처리
- 사실 검증: 생성된 응답의 정확성 확인
- 맥락 조정: 대화 흐름 또는 사용자 의도에 맞춘 응답 최적화
- 포맷 구조화: 보고서, 기술 문서 등에 맞는 표준 형식(예: 항목별, 목록 형식) 적용
6. 출력 전달
- 출력 형태:
- 자연어 텍스트: 고객 문의 응답, 보고서 생성, 문서 요약
- 구조화된 데이터: 대시보드, 보고서 내 추출된 통찰 및 사실
- 인터랙티브 응답: 챗봇 등에서 실시간 사용자 참여 유도
RAG 아키텍처 구성 요소
- 데이터 수집 계층: API, 데이터베이스, 웹 스크래핑 도구(Apache Kafka, Amazon S3)
- 검색 계층: 벡터 검색 엔진(FAISS, Elasticsearch), 문서 랭킹(BM25, neural ranking)
- 생성 계층: GPT-3, T5 모델, 토큰화 및 문맥 관리
- 출력 계층: NLP API, 감정 분석 도구 활용
RAG 기반 비즈니스 적용 효과
- 정확도 향상: 외부 데이터 기반의 맥락 맞춤형 응답 제공
- 효율성 증대: 자동화된 문서 생성, 고객 지원, 보고서 작성으로 수작업 시간 절감
- 확장성: 실시간 대규모 데이터 처리 가능
- 지속 학습: 대화 기반의 응답 품질 개선
도전 과제 및 고려사항
- 데이터 품질: 검색 데이터의 품질이 생성 결과의 정확도에 직접적으로 영향
- 지연 시간: 대규모 데이터 처리 시 검색-생성 연동 지연 발생 가능
- 윤리적 고려: 편향 및 오류 방지를 위한 책임 있는 AI 활용 필요
결론
- RAG 구현 시 팁:
- 벡터 검색 엔진(FAISS, Elasticsearch)과 트랜스포머 모델(GPT-3, T5)의 조합 활용
- 데이터 품질 관리와 실시간 처리 최적화에 중점을 두어야 함
- 윤리적 프레임워크 도입으로 편향 및 오류 방지
- 요약: RAG는 최신 지식 검색과 맞춤형 생성을 결합하여 복잡한 업무 프로세스 자동화에 효과적인 기술임.