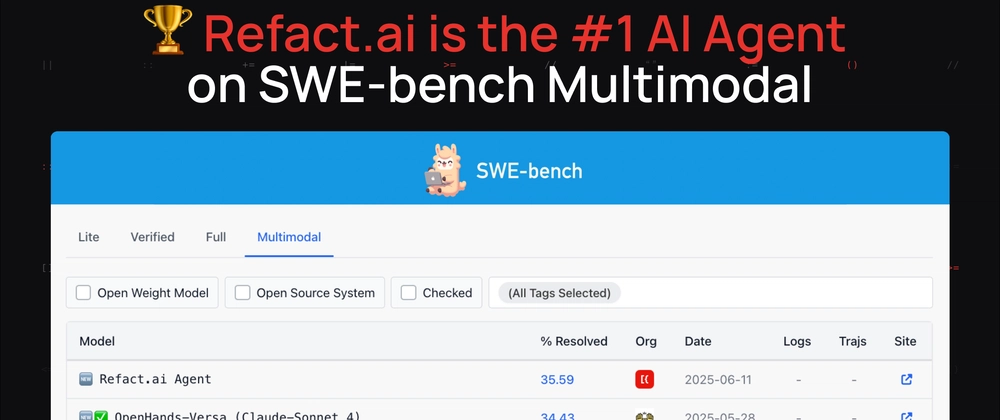
SWE-bench Multimodal: JavaScript 개발자에게 유리한 AI Agent 성과 공개
카테고리
프로그래밍/소프트웨어 개발
서브카테고리
웹 개발
대상자
JavaScript 개발자, AI Agent 설계자, 프론트엔드 개발자
핵심 요약
- Refact.ai Agent가 SWE-bench Multimodal에서 #1 성적 달성: 517개 중 184개(35.59%) 문제 해결, Claude 4 Sonnet 도입으로 74.40% 성적 기록
- Multimodal 테스트 특징: 스크린샷, 디자인 와이어프레임, 오류 메시지 등 텍스트+시각 정보 통합 테스트
- 핵심 기술:
debug_script()서브에이전트,compress_session()컨텍스트 관리, Claude 4 Sonnet 기반 자동 보호 장치
섹션별 세부 요약
1. SWE-bench Multimodal 개요
- 테스트 대상: 프론트엔드, UI 디자인, 데이터 시각화 등 웹 라이브러리 기반 문제
- 기존 SWE-bench Verified와 차이: Python 중심에서 JavaScript 환경의 실제 디버깅 상황 반영
- AI Agent 평가 기준: 스크린샷 기반 오류 해결, 시각적 컨텍스트 이해
2. Refact.ai Agent 성과
- 다른 AI Agent 대비 우위:
- SWE-bench Multimodal에서 35.59% 성공률
- SWE-bench Verified에서 pass@1 기준 최고 점수 달성
- Claude 4 Sonnet 도입 효과:
- 74.40% 성적 기록 (이전 Claude 3.7 기준 70.4% 대비 개선)
- 사고력 향상으로 strategic_planning() 도구 불필요
3. 문제 해결 전략
- 4단계 접근법:
cat(),search_symbol_definition()등으로 문제 탐색debug_script()사용해 오류 재현 및 디버깅- 디버깅 결과 기반으로 직접 파일 수정
compress_session()으로 컨텍스트 최적화 및 검증
- 자동 보호 장치:
- o4-mini 기반 디버깅 정보 요약
- 파일 과부하 방지: 5개 이상 파일 요청 시 경고
- 세션 종료 시 기존 테스트 무결성 확인
4. 성과 향상 요인
- 모델 업그레이드: Claude 4 Sonnet 도입
- 코드 최적화:
search_pattern()컨텍스트 확장,debug_script()프롬프트 미세 조정 - 자동화 강화:
strategic_planning()제거, 단일 세션 내 자동 해결
결론
- 실무 적용 권장사항:
- Claude 4 Sonnet 기반 AI Agent 사용 시 74.40% 성적 달성 가능
- debug_script() + compress_session() 조합으로 높은 신뢰도 유지
- 자체 호스팅 가능, 개발 도구(GitHub, Web, MCP) 통합 지원
- "Too many files" 방지 기능으로 파일 과부하 예방
- 요약: Refact.ai는 자동화된 디버깅, 실시간 컨텍스트 최적화, 실무 환경에서의 안정성을 통합한 AI Agent로, JavaScript 개발자에게 실질적 도움 제공.