디자인 스마트하게: 모바일 인터페이스 최적화를 위한 최상위 LLM 테스트
카테고리
디자인
서브카테고리
UX 디자인
대상자
- 대상자: UI/UX 개선에 관심 있는 개발자, 디자이너, AI 도구 활용자
- 난이도: 중간 (AI 도구 사용 경험 필요)
핵심 요약
- LLM 성능 차이 분명: Claude 4는 최소한의 지시로도 현대적인 UI 개선을 성공적으로 수행한 반면, GPT-4.x는 예상보다 부족한 결과를 보임
- 의존성 처리 어려움: GitHub Copilot은
expo-linear-gradient설치 문제로 인해 작업 중단 - AI 도구의 제한성: 시각적 스크린샷 생성은 혼합 결과, ChatGPT는 레이아웃 아이디어 제시는 가능하지만 구체적 실행은 어려움
섹션별 세부 요약
1. 테스트 목적 및 환경
- 목표: 다양한 LLM 모델이 모바일 앱 랜딩 화면의 UX 개선 능력을 평가
- 기준: 작업 시간, 변경 내용, 의존성 처리, 사용자 평가
- 테스트 대상: GitHub Copilot, Claude 4, Gemini, GPT-4.x
2. GitHub Copilot 테스트 결과
- 시간 소요: 약 15분
- 결과:
expo-linear-gradient설치 문제로 인해 작업 중단, 변경 내용 없음 - 평가: 1/5 (의존성 처리 실패로 인한 성능 저하)
3. Claude 4 테스트 결과
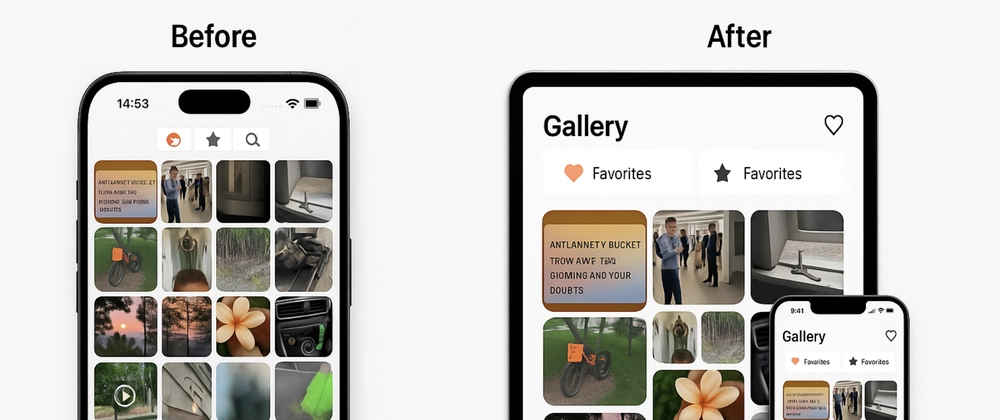
- 시간 소요: 약 7분
- 결과: gradient 배경, 폰트 스타일, 버튼 디자인 개선, 레이아웃 정리
- 평가: 4.5/5 (최소한의 지시로도 효과적인 UI 개선)
4. GPT-4.x 테스트 결과
- 시간 소요: 약 5분
- 결과: 미묘한 버튼 정렬 개선만 수행, 변화가 거의 없음
- 평가: 3/5 (예상보다 부족한 결과)
5. 시각적 스크린샷 생성 시도
- ChatGPT는 브릭 레이아웃 아이디어 제시, 하지만 실제 구현은 어려움
- 시도 결과: 텍스트 정렬 시도 실패, 이미지 생성은 혼합 결과
결론
- Claude 4는 최소한의 지시로도 효과적인 UI 개선 가능, GPT-4.x는 특정 상황에서 성능 저하
- AI 도구 활용 시:
- 의존성 처리에 주의 (예:
expo-linear-gradient설치 문제) - 모델 선택이 결과에 큰 영향을 미침 (Claude 4 추천)
- AI와의 대화를 통해 명확한 요구사항 정의 (예: "gradient 배경 추가" 등 구체적 지시)