Train LLMs to Talk Like You on Social Media, Using Consumer Hardware
카테고리
프로그래밍/소프트웨어 개발
서브카테고리
개발 툴
대상자
LLM 트레이닝 및 토이 프로젝트에 관심 있는 개발자, 데이터 과학자, 소프트웨어 엔지니어.
난이도: 중급~고급, 소프트웨어 개발 및 머신러닝 경험 필요.
핵심 요약
- *LLM 트레이닝을 소비자 하드웨어로 구현하는 방법**
- PEFT 기법(Parameter-Efficient Fine-Tuning)을 활용해 VRAM 제한을 극복할 수 있음.
- QLoRA(Quantized LoRA)는 4비트 정밀도로 모델 크기 축소 및 하드웨어 요구 사항 감소.
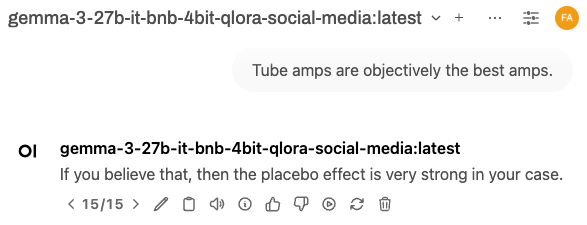
- 소셜 미디어 데이터를 활용해 사용자 스타일을 반영한 답변 생성 가능.
섹션별 세부 요약
1. 왜 파인튜닝인가?
- 시스템 프롬프트와 RAG(Retrieval-Augmented Generation)는 제한된 유연성을 제공하지만, 파인튜닝은 데이터셋 기반 스타일 변환 가능.
- 파인튜닝은 모델의 응답 형식 및 스타일을 근본적으로 변경할 수 있지만, 지식 범위는 제한적.
- 논리적 사고 모델에는 적합하지 않음.
2. 어떤 모델을 선택해야 하나?
- 27B/8B 규모 모델은 소비자 하드웨어에서 파인튜닝 가능 (예: Gemma 3 27B, Llama 3.1 8B).
- 100B 이상 모델은 일반적인 소비자 하드웨어로는 불가능.
- 모델 선택 시 정밀도 및 VRAM 요구 사항을 고려해야 함.
3. 어떤 하드웨어가 필요하나?
- RTX 3090(24GB VRAM)은 27B 모델 파인튜닝 가능, RTX 5090은 VRAM 32GB로 성능 향상.
- SSD는 주 드라이브 필수, HDD는 대용량 데이터 저장용으로 사용 가능.
- 메모리(64GB)는 최소 요구 사항, 더 많은 메모리로 디스크 캐시 성능 향상.
4. 기술 및 라이브러리
- PEFT(Parameter-Efficient Fine-Tuning) 기법은 모델 가중치 대부분 고정하고 일부만 조정.
- LoRA(Low-Rank Adaptation)는 저ank 행렬을 추가해 파인튜닝 효율성 향상.
- QLoRA는 4비트 정밀도로 메모리 사용량 감소.
- Unsloth 라이브러리는 소비자 GPU에 최적화된 파인튜닝 프로세스 제공.
5. 데이터셋 구성
- 소셜 미디어 댓글을 데이터셋으로 활용 가능 (예: Reddit 댓글).
- PRAW 라이브러리로 부모 댓글/포스트 추출 및 CSV 형식 저장.
- Markdown 형식 유지해 모델의 포맷 학습 가능.
- 자신의 데이터를 사용해 호환성 검증 및 허위 정보 감지 용이.
결론
- 소비자 하드웨어로 LLM 파인튜닝은 PEFT 기법과 QLoRA를 통해 가능.
- Unsloth 라이브러리 사용 시 홈 PC에서 빠른 파인튜닝 가능.
- 소셜 미디어 데이터를 활용해 사용자 스타일 반영한 모델 생성 가능.
- 클라우드는 생산 환경에서 고성능 GPU를 제공하는 최적 선택.